

올리브영에서 순위가 의미하는 것
제조업 기반 뷰티 회사의 브랜드사업부에서 일하고 있다.
올리브영은 국내 뷰티 유통의 바로미터다. K-뷰티 브랜드가 자기 포지션을 확인하는 첫 번째 창구이자, 소비자가 "요즘 뭐가 좋아?"를 검색하는 곳이다. 여기서 검색 순위는 단순한 숫자가 아니다. 순위가 곧 노출이고, 노출이 곧 오가닉 매출이다.
그래서 올리브영은 순위 싸움이 치열하다.
브랜드들은 챌린저스, 스토어링크 같은 체험단 서비스를 상시로 돌리면서 순위를 유지한다. 체험단으로 구매를 발생시켜 검색 순위를 끌어올리고, 그 노출량으로 오가닉 매출을 잡는 구조다. "오늘의 특가" 같은 하루짜리 프로모션 날에는 더 노골적이다. 특정 시간대에 체험단 구매를 집중시켜서 카테고리 1위를 점유하고, 그 순간의 스크린샷을 마케팅 소재로 쓴다. "올리브영 여드름 패치 1위" 같은 문구, 한 번쯤 본 적 있을 거다.
이게 올리브영의 현실이다. 그리고 이 현실에서 살아남으려면, 경쟁사가 뭘 하고 있는지 알아야 한다.
알고 싶은 건 순위가 아니라 행동이다
"우리 제품 순위가 몇 위야?"보다 중요한 질문들이 있다.
경쟁사 A가 이번 주에 체험단을 돌렸나? 오늘의 특가를 진행한 날, 하루 종일 1위를 점유했나? 그래서 프로모션 이후 2주간 리뷰가 몇 개 늘었나? 리뷰 이벤트 리워드 수준은 어느 정도였나?
이런 분석을 하려면 매일매일의 데이터가 쌓여야 한다. 경쟁사의 순위 변동, 리뷰 증가량, 프로모션 시작과 종료 시점, 신규 진입 제품. 이걸 하루 단위로 축적하면, 경쟁사의 행동 패턴이 보이기 시작한다.
매출까지는 알 수 없다. 그건 그들의 영업비밀이니까. 하지만 리뷰 증가량은 추적 가능하다. 프로모션 전후 리뷰 변화를 보면 체험단 규모를 역추산할 수 있고, 그 데이터가 쌓이면 "어떤 액션이 어느 정도의 효과를 내는지"가 윤곽이 잡힌다.
순위를 "확인"하는 건 의미가 없다.
경쟁사의 행동과 그 결과를 추적하는 것. 그게 목적이다.
근데 이걸 매일 팀원에게 시키는 건 말이 안 된다. 올리브영 사이트에 들어가서 6페이지 넘기면서 129개 제품을 일일이 확인하고, 어제 데이터랑 비교해서 변화량을 계산하고, 엑셀에 정리하고. 이 작업에 30분에서 1시간. 매일. 한 달이면 그 팀원의 근무 시간 10%가 이 소모적인 작업에 쓰인다.
올리브영 크롤링 자동화, 구현은 생각보다 단순하다
이 시스템에 거창한 기술은 필요 없다. Python, GitHub Actions, Google Sheets. 이 세 가지면 충분하다. 서버도 필요 없고, DB도 필요 없고, 인프라 비용도 0원이다.
전체 파이프라인은 5단계로 돌아간다.
# 파이프라인 전체 흐름
def run(self):
previous = sheets.get_previous_data() # 1. 전일 데이터 조회
products = crawler.crawl() # 2. 올리브영 크롤링
processed = processor.process( # 3. 변화량 계산
products, previous
)
sheets.save(processed) # 4. Sheets 저장
teams.send(processed) # 5. Teams 리포트크롤링에서 알림까지, 매일 아침 자동으로 돈다. 실행 시간 1분 45초.
하나씩 풀어보겠다.
1단계: 올리브영 크롤링
Selenium으로 headless Chrome을 띄우고, 올리브영 검색 페이지를 6페이지 순회하면서 데이터를 긁는다. 올리브영 검색 페이지는 CSS 셀렉터 기반으로 깔끔하게 파싱된다.
# CSS 셀렉터 기반 데이터 추출
product_name = element.find_element(By.CSS_SELECTOR, ".prd_name").text
brand = element.find_element(By.CSS_SELECTOR, ".tx_brand").text
discount_price = element.find_element(By.CSS_SELECTOR, ".tx_cur .tx_num").text
reviews = element.find_element(By.CSS_SELECTOR, ".prd_review_cnt").text제품명, 브랜드, 정가, 할인가, 할인율, 리뷰수, 평점, 프로모션, URL. 제품 하나당 9개 필드를 추출한다. 6페이지를 돌면 129개 제품 전체가 모인다.
프로모션 감지는 패턴 매칭으로 처리한다. "1+1", "2+1", "증정", "오늘드림", "세트할인", "쿠폰". 올리브영이 프로모션을 텍스트로 표시하는데 형식이 제각각이라, 키워드 기반으로 잡아내야 한다. 경쟁사가 오늘의 특가를 시작했는지, 증정 이벤트를 걸었는지가 여기서 포착된다.
2단계: 전일 대비 변화 계산
크롤링만 하면 "오늘의 스냅샷"일 뿐이다. 가치를 만드는 건 전일 데이터와의 비교다.
Google Sheets에 쌓인 전일 데이터를 불러와서, 제품명+브랜드 조합으로 매칭한 뒤, 변화량을 계산한다.
# 전일 대비 변화량 계산
key = f"{brand}::{name}"
if key in previous_lookup:
prev = previous_lookup[key]
rank_change = prev.rank - today.rank # 양수 = 순위 상승
review_increase = today.reviews - prev.reviews
review_growth = (review_increase / prev.reviews) * 100
price_change = today.discount_price - prev.discount_price
else:
is_new = True # 신규 진입 제품이 비교 데이터가 있으니까 이런 분석이 가능해진다. "경쟁사 A가 어제 오늘의 특가를 진행했고, 당일 1위를 점유했다. 그 이후 2주간 리뷰가 +73개 늘었다." 단순히 순위가 오르내렸다는 사실이 아니라, 경쟁사의 행동과 그 결과를 데이터로 추적할 수 있게 된다.
3단계: Google Sheets 저장
데이터를 어디에 저장할지 고민하다가 Google Sheets를 선택했다. 이유는 두 가지다.
서버가 필요 없다. SQLite를 쓰면 파일을 호스팅해야 하고 서버 비용이 생긴다. Google Sheets는 Google이 호스팅해준다.
그리고 팀원이 직접 볼 수 있다. DB에 쿼리를 날리는 건 개발자의 영역이지만, 스프레드시트는 누구나 연다. 리포트 외에 원본 데이터를 직접 분석하고 싶을 때, 링크 하나면 된다.
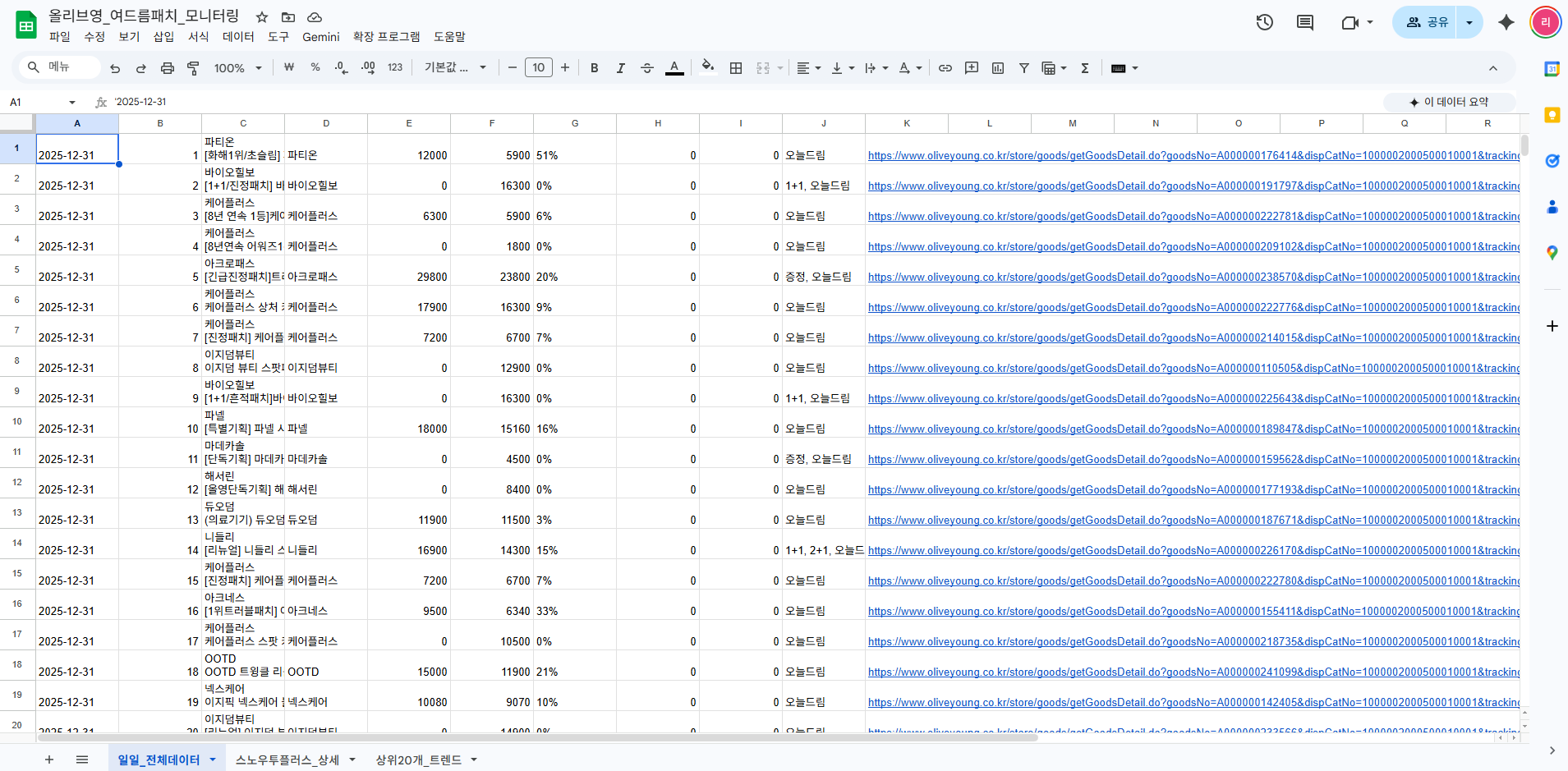
시트 3개로 관리한다.
일일_전체데이터: 129개 제품 전체. 날짜, 순위, 브랜드, 가격, 리뷰수, 프로모션, URL. 카테고리 전체를 조망하는 원본이다.
스노우투플러스_상세: 자사 제품만 필터링. 순위 변동, 리뷰 증가, 가격 변동 포함. 일일 성과를 한눈에 확인.
상위20개_트렌드: 경쟁 상위 20개 제품의 변화 추적. 누가 올라오고, 어떤 프로모션이 효과를 내고 있는지. 경쟁 분석의 핵심 시트다.
90일이 지난 데이터는 자동으로 정리된다. 분기 분석에는 충분하고, 시트가 비대해지는 걸 방지한다.
4단계: GitHub Actions로 매일 자동 실행
매일 아침 9시에 돌아야 한다. 서버를 띄우면 비용이 발생하니까, GitHub Actions를 썼다.
# .github/workflows/oliveyoung-monitor.yml
on:
schedule:
- cron: '0 0 * * *' # UTC 00:00 = KST 09:00
workflow_dispatch: # 수동 실행도 가능GitHub Actions 무료 티어는 월 2,000분이다. 이 워크플로는 한 번에 1분 45초. 매일 돌려도 월 53분. 무료 한도의 2.6%.
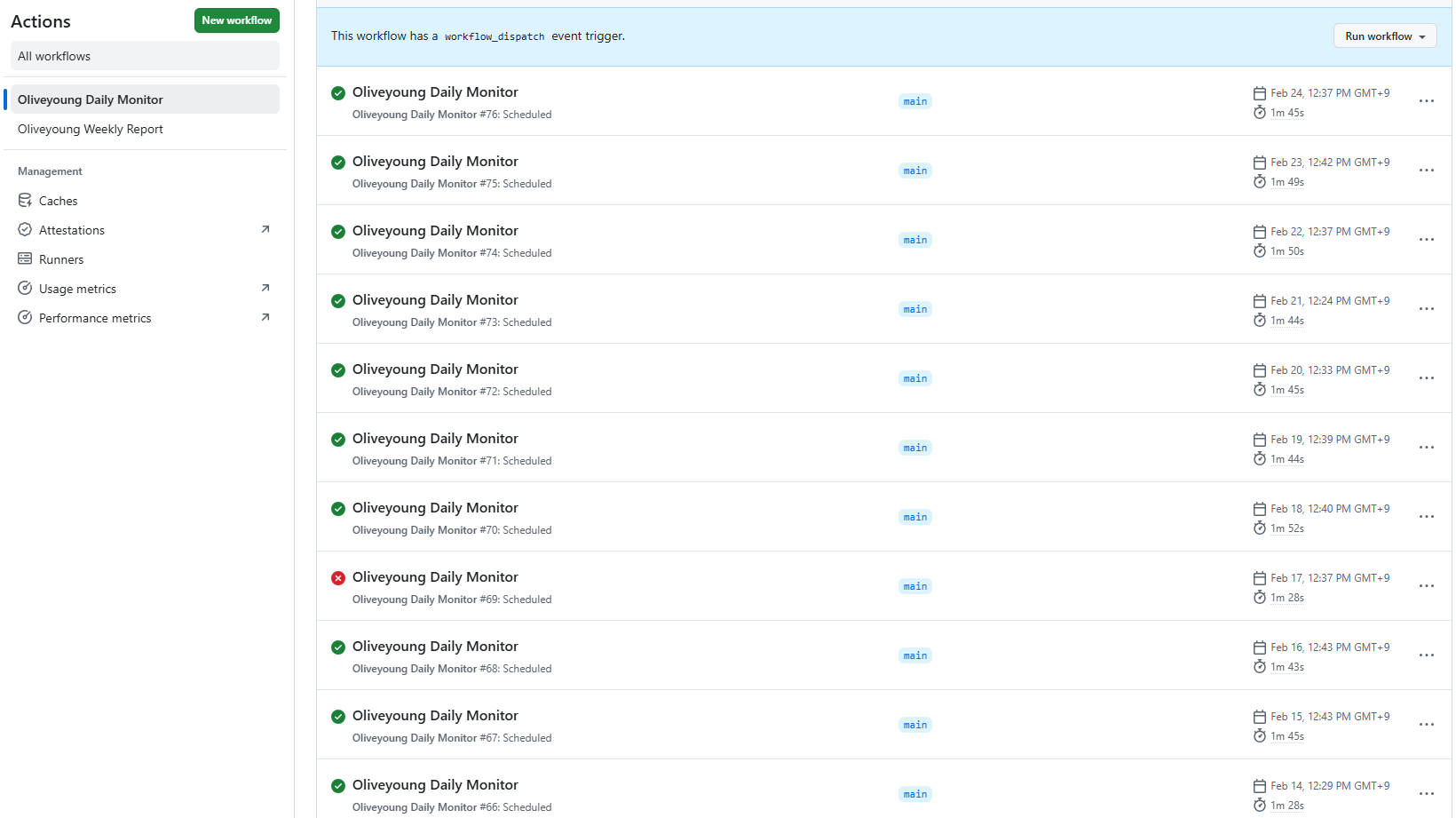
76회 연속 성공이다. 12월 말부터 매일 돌아가고 있고, 한 번도 실패하지 않았다. 크롤링 실패 시 5초 후 재시도, 최대 3번. 3번 다 실패하면 Teams로 에러 알림을 보내는데, 실제로 에러 알림이 온 적은 없다.
SIGNAL에서 쿠팡 광고센터 크롤링이 매일 새벽에 죽어서 고생했던 것과는 대조적이다. 올리브영 검색 페이지는 구조가 안정적이라 headless Chrome으로 단순하게 긁어도 깨지지 않는다.
5단계: Power Automate로 Teams 알림
크롤링 결과를 Teams로 보내는 데 Power Automate를 썼다. MS 365를 쓰는 회사라면 이미 라이선스가 있으니 추가 비용이 없다.
연결은 간단하다. Power Automate에서 "HTTP 요청을 받을 때" 트리거로 워크플로를 만들면 HTTP POST URL이 생성된다. Python에서 이 URL로 메시지를 POST 하면, Power Automate가 받아서 Teams 채팅에 올려준다. Webhook URL 하나면 끝이다.
# Teams 알림 발송
def send(self, processed_data):
message = self._build_text_message(processed_data)
requests.post(
self.webhook_url,
json={"text": message},
headers={"Content-Type": "application/json"}
)매일 아침, 이런 리포트가 온다
Teams를 열면 이런 리포트가 와 있다.
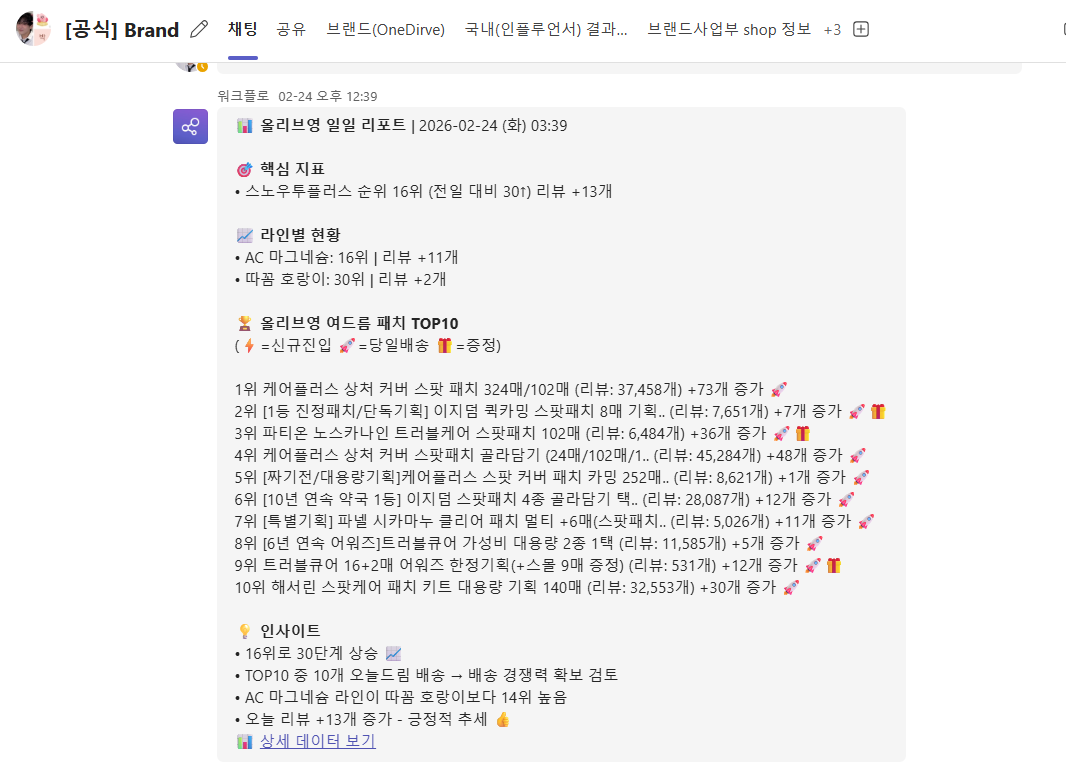
핵심 지표: 자사 제품의 오늘 순위, 전일 대비 변동, 리뷰 증가. 이것만 봐도 오늘 상태가 파악된다.
라인별 현황: 제품 라인별 순위와 리뷰 변동. 어떤 라인이 밀리고 있는지 빠르게 캐치.
TOP 10: 카테고리 상위 10개 제품의 상세 현황. 신규 진입, 당일배송, 증정 프로모션 여부가 아이콘으로 표시된다. 경쟁사가 오늘 뭘 시작했는지가 여기서 다 보인다.
인사이트: 데이터 기반 코멘트. "TOP10 중 10개 오늘드림 배송, 배송 경쟁력 확보 검토" 같은 액션 가능한 분석이 자동으로 생성된다.
이전에는 브랜드 매니저가 30분 걸려 직접 확인하던 정보가, 이제 Teams를 여는 것으로 끝난다. 그것도 전일 대비 변화량, 경쟁사 프로모션 동향, 인사이트까지 포함해서.
그리고 진짜 가치는 이 데이터가 90일치 쌓였을 때 나온다. 경쟁사 A가 분기에 몇 번 오늘의 특가를 진행하는지, 체험단을 돌린 후 평균 리뷰 증가량이 얼마인지, 어떤 리워드 수준의 리뷰 이벤트가 효과적인지. 일일 데이터의 축적이 경쟁 인텔리전스가 되는 순간이다.
결과
자동화 달성도
- 경쟁사 추적: 129개 제품, 매일 자동 수집 + 전일 대비 비교
- 프로모션 감지: 1+1, 증정, 오늘드림, 세트할인, 쿠폰 자동 포착
- 리뷰 분석: 일별 리뷰 증가량, 성장률 추적 (체험단 규모 역추산 가능)
- 리포트 발송: 매일 오전 Teams 자동 알림 + 인사이트
- 데이터 보관: 90일 자동 관리, Google Sheets 직접 조회 가능
- 장애율: 0% (76일 연속 무장애)
돌아보며
이 프로젝트는 ONE STOCK이나 SIGNAL에 비하면 작다. Python 파일 6개, 전체 코드 800줄. React도 없고, Express도 없고, AI도 없다. 가장 기본적인 도구들만 썼다.
그런데 현장에서 가장 먼저 효과를 본 프로젝트가 이거다.
브랜드 매니저가 매일 아침 제일 먼저 Teams 리포트를 확인하고, 경쟁사 동향에 따라 그날의 마케팅 대응을 결정한다. 경쟁사가 체험단을 돌리기 시작했으면 우리도 대응 타이밍을 잡고, 오늘의 특가 이후 리뷰 증가 추이를 보면서 다음 프로모션 설계에 반영한다. 수동으로 30분 걸리던 작업이 사라진 것도 의미가 있지만, 이전에는 아예 불가능했던 "90일 치 경쟁 행동 패턴 분석"이 가능해진 게 더 크다.
Python과 Selenium으로 크롤링하고, Google Sheets에 쌓고, GitHub Actions로 매일 돌리고, Power Automate로 Teams에 보낸다. 거창한 인프라 없이, 이미 있는 도구들의 조합만으로 충분하다. 비용은 0원이고, 한번 세팅하면 알아서 돌아간다.
올리브영에서 경쟁사 모니터링이 필요한 사람이라면,
이 정도 시스템은 누구나 만들 수 있다. 도구는 다 무료다.
다음 단계는 키워드 확장이다. 지금은 "여드름 패치" 하나만 추적하지만, "트러블 패치", "스팟 패치" 같은 관련 키워드를 추가하면 카테고리 전체의 시장 지형이 보인다. 그리고 이 데이터가 SIGNAL에 연동되면, 올리브영 경쟁 데이터를 포함한 통합 마케팅 인텔리전스가 완성된다.